Case studies
Document digitization: information extraction using AI

Habacus, a visionary startup operating in the FinTech market, firmly committed to supporting academic and vocational training to enhance human capital and generate innovation, asked Pi School for help to speed up document information extraction using AI.
During Pi School of AI Session 11, fellows Xinyi Chen and Maahin Rathinagiriswaran worked on a challenge in document digitization. They built an end-to-end Deep Learning system capable of extracting textual information from document images without relying on standard OCR tools.
Do you have a challenge in document digitization? We can help you!
Document understanding is the automated process of reading, interpreting, and extracting information from the written or printed texts contained within the pages of a document image or scan.
Before the advent of AI-powered Document Processing, document digitization required people to step in and process documents manually. From a human perspective, this process is repetitive and tedious. While for companies, it is expensive, time-consuming and prone to human error.
With the development of Deep Learning algorithms, various helpful Visual Document Understanding (VDU) models have been developed to extract information automatically from paper documents.
Current VDU methods tend to solve the task in a two-stage manner:
- reading the texts in the document image, relying on Deep Learning-based Optical Character Recognition (OCR) techniques;
- holistic document understanding.
Although these models achieve good performance in solving the task, the OCR-dependent approach is expensive to train as it requires extra labeled data for image parsing and lacks generalization abilities to deal with different languages and domain changes.
To meet the company’s needs, our AI fellows adopted an end-to-end model called Donut, which performs a direct mapping from a raw input image to the desired output without OCR. This model is based on the Transformer architecture and was introduced in October 2022 in “OCR-Free Document Understanding Transformer“.
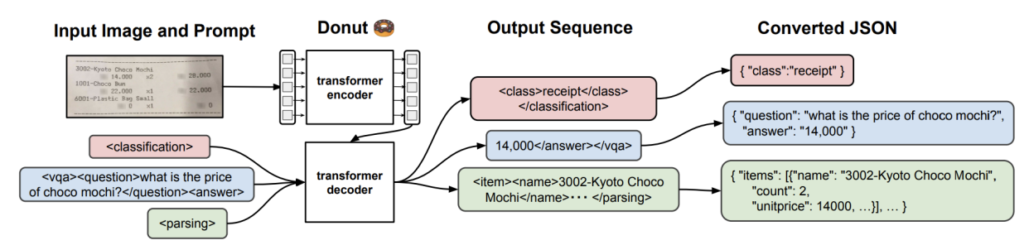
We leveraged Donut in two different modes: Document Parsing (DP) and Visual Question Answering (VQA). DP is the task of extracting the entirety of the textual information contained in a document, whereas VQA aims to extract specific bits of information based on questions formulated in natural language. Donut is an OCR-free end-to-end Visual Document Understanding model that uses an encoder-decoder Transformer architecture and consists of an image Transformer encoder and an autoregressive text Transformer decoder.
In other words, it encodes the image into token vectors, which it can then decode or translate into an output sequence, which is then organized in a data structure.
Figure 3 offers an overview of how Donut works.
Transformers are a type of Artificial Neural Network architecture used to solve the problem of transduction or transformation of input sequences into output sequences in Deep Learning applications. The original Transformer is a sequence-to-sequence model for Machine Translation which has shown significant quality in translating from English to other languages, but nowadays it is used for a wide variety of sequence-related tasks.
Transformers are based entirely on attention mechanisms, making them incredibly efficient compared to RNNs or CNNs.
The Habacus project focused on extracting information from academic documents, but it could be extended to other document types. Successful applications of the model would help human operators digitize document images more quickly. This method has obtained an accuracy score of 88.21% on student academic documents across five different templates by fine-tuning the Donut model in DP mode.
On the other hand, the same model in VQA mode obtained an accuracy score of 41.33% with generic Italian questions fed into the model and 66.85% with generic English questions.
These accuracy scores were obtained using a test set with a sample size of 1215.