Live Webinar
Shaping Unstructured Data into Valuable Information
Unstructured data shouldn’t be a bottleneck. It should be an advantage.
Join Pi School’s Machine Learning Scientist, Vijayasri Iyer, for a live webinar and discover how to transform free text into structured, usable data using Trallie.
Trallie is an open-source framework based on Large Language Models, developed by Pi School for the Next Generation Internet initiative, a programme launched by the European Commission.

Unstructured data, which refers to free-form text lacking a predefined format, is everywhere. It is present in documentation, asset records, and legacy systems and often provides the only available descriptions of resources, objects and people. While easy for humans to read, this type of data isn’t organised in a way that supports efficient searching, querying, analysis, or automation.
Imagine you’re a compliance analyst at a bank, trying to extract risk indicators from thousands of financial reports in wildly inconsistent formats—PDFs, scanned documents, etc. Or maybe you’re a scientist building a gene-disease dataset from research papers, forced to manually label examples every time your schema changes. Or a cybersecurity support lead, buried in unstructured incident reports while leadership demands dashboards with structured insights. In all these cases, the challenge is the same: critical information is locked in free-text, and traditional information extraction methods—rigid, annotation-heavy, and brittle—just can’t keep up. These are just a few examples of a common problem: turning unstructured data into structured, queryable data.
Traditionally, turning natural language into structured data means using information extraction techniques like named entity recognition, template filling, and entity resolution. However, these systems are very rigid and labour-intensive: people have to define all the categories and label several examples just to train a custom model. Any change to the annotation schema requires manual re-labelling and fine-tuning, making the process costly and time-consuming. This is slow, expensive, and difficult to scale.
Introducing Trallie: Transfer Learning for Information Extraction
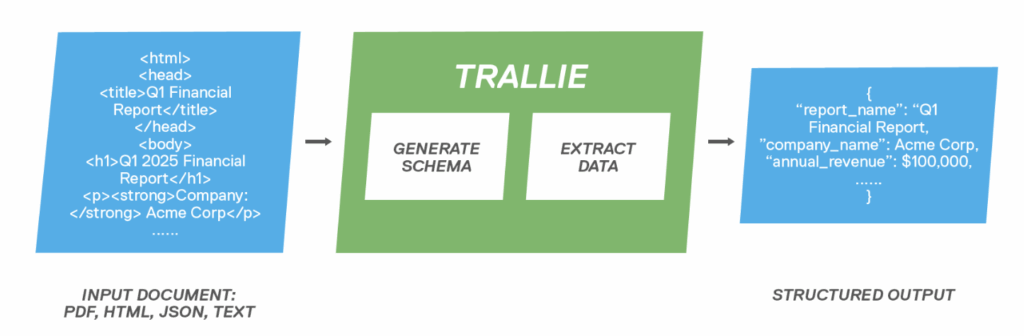
This is where Trallie comes in. Trallie is a framework that leverages the power of large language models (LLMs) to reimagine information extraction (IE) with or without user guidelines. Instead of relying on labelled examples or copious amounts of training on your data collection, Trallie requires very few or no representative examples of the data to convert into a structured format.
Trallie operates with three core objectives:
- Minimal manual annotation: Powerful, well-trained LLMs only require a few examples that are encapsulated in a prompt (set of instructions) to deliver high-quality results.
- Flexibility with document formats and languages: Trallie can adapt well to raw text in HTML, PDF, TXT and JSON formats. In addition it also supports 5 EU languages: English, French, Italian, German and Spanish.
- Accessibility to non-expert users: Current structured data extraction systems based on LLMs have proven to be excellent when extracting data from a user that knows what to extract in advance. However this may not always be the case, since the expectation here is that of a domain expert. Trallie automatically infers the schema from a set of documents, allowing the user to modify it as needed for extraction.
Current methods don’t fully leverage the strengths of LLMs beyond prompt engineering. While LLMs can reason and manipulate NL as they do with code, most approaches don’t exploit this potential. The challenge is not just recognising entities but understanding how to extract, structure, and adapt information dynamically.
In addition to the examples provided above, Trallie can also be applied to several information extraction problems across multiple domains, including legal, healthcare, finance, and scientific data. Information extraction plays a critical role in unlocking the value of unstructured data—but too often, it becomes a bottleneck. Trallie removes this constraint by making information extraction more agile and adaptive, reducing reliance on costly human annotation while harnessing the full capabilities of large language models (LLMs) to deliver fast, flexible, and high-quality structured outputs.
Trallie was developed by Pi School under the 4th Open Call of the Next Generation Internet (NGI) initiative—a programme launched by the European Commission to create a more human-centric, open, and resilient Internet. This collaboration supports NGI’s broader mission to foster cutting-edge, privacy-respecting technologies that empower users and improve access to information across diverse sectors.
Pi School brings its expertise in artificial intelligence to develop custom AI solutions tailored to your specific needs, helping businesses transform business challenges into strategic advantages.
Join us on November 26
at 5:00 PM
on Zoom
Register Now
Live Webinar: Trallie
Join us on November 26, at 5:00 PM.